- Русский
- English
- Português
Automating News Collection and Summarization with Bright Data and OpenAI
Learn how to automate news collection and analysis using Bright Data and OpenAI to generate real-time market signals. This article covers setting up a no-code workflow, filtering noise with GPT-4, and real-world use cases for AI in the crypto space. Get ahead of the competition by transforming data chaos into high-quality analytical digests.

«In the eight years we’ve been parsing all kinds of data, we have tried 43 different approaches to automating news summaries. The main conclusion? Without a combination of proxy infrastructure and GPT models, you either get outdated data or mountains of junk that you will still have to filter manually afterward.» I use Bright Data for effortless collection and OpenAI for analysis and context understanding. It is an ideal synergy — something no RSS feed can provide.
And here is what is truly interesting—the combination of proxies and AI really takes the quality and relevance of news data to a completely different level.
Introduction
The cryptocurrency market and its investments live in short cycles of 4–6 hours. Information about a token listing on Binance can drive the price up by 40% in two hours, followed by a pullback. If you only receive news from a morning digest, you’ve already fallen behind. Automated news parsing transforms this speed into money: it collects signals from over 200 sources, filters out the noise, and delivers a ready, prioritized digest.
The times of long information verification were those unfortunate days when this difficult work was performed by a whole team of analysts, each with a salary starting at three thousand dollars. Every day, they manually checked information from CoinDesk, Bloomberg, Telegram, and even forums. Now, everything is replaced by a single workflow that processes data 24/7 without weekends and never misses an important signal.
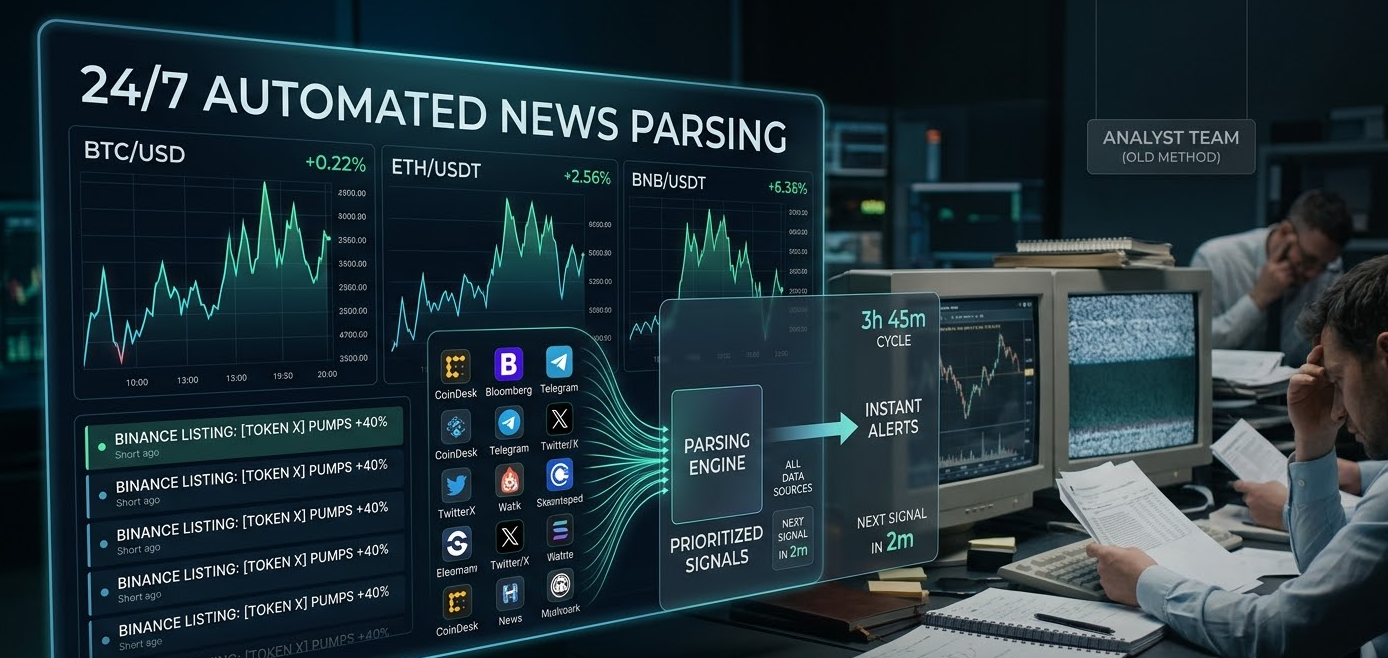
Why automation has ceased to be a luxury and become a necessity:
- Speed
Manually obtaining data from assistants takes 90–120 minutes. During this time, the market manages to change twice. OpenAI GPT summarizes 500 news items in 30 seconds and returns a structured report with key takeaways—90% faster than humans. - Scale
Physically, a person cannot monitor more than 15–20 channels simultaneously. Bright Data indexes 300+ sites in parallel, including closed forums and paid analytical platforms. - Bias, Emotion, and Fatigue
Up to 30% of important signals are ignored by analysts due to cognitive biases and fatigue. Automation ignores nothing, including weak signals that could grow into trends within a few hours.
Time is money. Everything must work quickly and precisely.
Overview of Bright Data and OpenAI GPT Capabilities for News Information
Bright Data is an infrastructure of 72 million IP addresses in 195 countries. It is not just a proxy: the platform offers ready-made scrapers for news sites, automatic IP rotation, and CAPTCHA bypassing. You get up-to-date information without blocks, even from restricted sites.
OpenAI GPT is a language model that organizes the chaos of hundreds of headlines into a prioritized report. GPT-4 Turbo understands context: it distinguishes fakes from reliable publications, extracts key facts, and provides summaries in any language. In contrast to RSS aggregators, the model finds connections and causes rather than just announcing a headline and a link.
How the synergy works:
- Bright Data collects news from 200+ sources in 15 minutes, including paid platforms and private forums.
- OpenAI API removes duplicates: it sorts by importance and generates three types of summaries: short (3 points), medium (10 points), and long (where links are sorted, quoted, and consolidated).
- Notifications arrive in Telegram or via email, providing detailed summary data: headline, key takeaway, source, publication time, and impact forecast (low/medium/high).
Technically, this is a chain: HTTP request to Bright Data API → JSON transfer to GPT-4 → generation of the final digest via ASCN.AI. In short, even without the help of programmers, you only need to configure triggers and nodes.
What is Automated News Scraping?
Web scraping is the automated extraction of data from websites. This usually involves HTTP requests to pages and the extraction of necessary elements via HTML, CSS, or JavaScript. However, modern websites complicate the task with dynamic loading (React, Vue), anti-bot protection (Cloudflare, reCAPTCHA), and frequent layout changes.
Main methods of news parsing:
- HTML parsing via CSS and XPath
Suitable for static sites. We send a request, get the HTML, and extract the required blocks (e.g., .article-title). This method is simple but very fragile—if the layout changes, the parser breaks and needs manual fixing. - JavaScript rendering with headless browsers
For sites where content is loaded dynamically (TechCrunch, The Block), Puppeteer or Playwright are used to emulate a browser, run JS, and then extract data. The downside is it’s 5 times slower and puts a heavy load on the server. - API Integrations
Some social networks and platforms (such as Reddit, Twitter, Telegram) provide official APIs that return clean JSON data. This is reliable but only works for about 20% of all sources. - RSS Aggregation
The simplest option for reading is, of course, RSS feeds, but they have limitations. Information can lag by 10–30 minutes, and full text is often missing.
Common errors of self-written parsers:
- Rate limiting: IP blocking after 50–100 requests per minute.
- User-Agent detection: The site refuses to process requests without a proper browser header.
- JavaScript challenges: Cloudflare refuses to respond without executing JS code.
- Site structure changes: Parsers stop working after a redesign.
Bright Data solves these problems with ready-made Web Unlocker scrapers: bypassing protection, rotating IPs, and adapting to changes using machine learning.
Tools and Platforms, including Bright Data
| Tool | Processing Time (1000 pages) | Protection Bypass | Starting Price | Code Required? |
|---|---|---|---|---|
| BeautifulSoup | 2-3 hours | No | Free | Yes |
| Octoparse | 2-3 hours | Partial | $75/mo | No |
| Bright Data | 10-15 minutes | Yes | $500/mo | No |
| Custom Parser + Proxy | 1-2 hours | Manual | $200+/mo | Yes |
For traders and investors, speed and reliability are vital: every missed minute is missed profit. If the parser goes down during a crisis, data will be lost, and that is expensive. Bright Data provides immediate insurance against this.
The Role of AI in News Processing and Analysis
Collecting 300 news items is easy. The key is to filter the noise, highlight the essentials, and set priorities. A human does this in an hour; a machine does it in 30 seconds. AI also captures weak signals that often escape analysts under pressure.
AI is capable of recognizing hidden patterns and trends invisible to the human eye. Here is what AI performs better than a human:
- Deduplication
The same news appears on many sites—GPT-4 finds the similarity and leaves only the unique source, usually the most authoritative or the first to publish. - Sentiment Analysis
The model determines the tone (positive, negative, neutral) and identifies mood triggers. For example: "SEC delays decision on Bitcoin ETF" is a negative signal, even if the word "negative" isn't in the sentence. - Key Fact Extraction
This is not mechanical extraction, but a meaningful analysis tailored to your needs (DeFi, Venture Capital, Crypto-investing).
Real-world example with numbers:
Input: 47 messages about the drop in the XRP token over a 6-hour midday period (Sources: CoinDesk, Bloomberg, Twitter, Telegram).
Output via GPT-4:
- Deduplication → 12 unique sources.
- Sentiment Analysis → 8 negative, 3 neutral, 1 positive (analyst's counter-argument).
- Fact Extraction → Identified: "SEC filed a lawsuit against Ripple Labs for an unregistered securities offering" (Bloomberg, 14:32 UTC).
Summary:
«XRP collapsed by 18% in 4 hours after the SEC filed a lawsuit. The main accusation is the sale of unregistered securities worth $1.3 billion. The market is engulfed in sell-offs: trading volume tripled, and Binance funding rates turned negative (-0.15%). Counter-opinion: Ripple lawyer John Deaton considers the lawsuit unlawful and predicts its withdrawal within 30 days. Forecast of market sentiment: high negative (volatility 15-25%).
Without AI, these news items would have scattered your attention across 47 headlines, and you might have even missed the most important part if you only monitor 5–10 sources.
How News is Summarized using OpenAI GPT
OpenAI GPT is a language model trained on gigabytes of text. For news purposes, we use GPT-4 Turbo with a massive context window of 128,000 tokens, which is about 300 pages of text in a single request.
Summarization algorithm:
- Preprocessing
HTML arrives from the parser, which is cleaned of ads and navigation, leaving only the content of the article itself. - Tokenization
The text is broken into parts (tokens), allowing the model to work confidently even with typos and slang like "hodl" or "DeFi." - Contextual Compression
GPT identifies important sentences using extractive summarization and then reformats the text through abstractive summarization for clarity. - Ranking
Each text snippet is assigned a relevance score; only the most important ones (over 0.7) make it into the final summary. - Final Text Generation
The model forms a report based on a given prompt, for example:Summarize these 50 crypto news articles in 5 bullet points. Focus on: market impact, key figures, time of events.
The result is a concise and clear list with dates, quotes, and links.
Quality is influenced by:
- Temperature (from 0 to 1)
Controls the model's creativity. For news editing, it’s usually 0.2–0.3—less fiction, just facts.
Why GPT surpasses traditional classics like TF-IDF or TextRank:
- Context—It distinguishes homonyms, for example, "rate" as an exchange rate vs. "rate" as a ranking.
- Multilingualism—It translates and compresses news in different languages within a single request.
- Adaptability—Using fine-tuning, the model can be tailored to specific tasks in DeFi and crypto news.
Specific example: On October 11, 2024, we collected 120 news items about the BTC flash crash (from $68K to $58K in 2 hours). Manual analysis would have taken about 3 hours; GPT took 40 seconds and provided this brief:
"Cause: Liquidation of $2.1 billion in 'long' positions on Binance and Bybit after a cascade of stop-orders were triggered below $66,000 amid the price decline. An additional trigger was the Fed Chair's statement on a 0.5% rate hike. Forecast: 10-15% correction and recovery within 48-72 hours (similar to events in 2021-2023)."
This is not just a retelling—it is analytics with a cause-and-effect model.
Integrating Bright Data with OpenAI for Automated News Digest Creation
The combination of Bright Data and OpenAI is integrated via API using the no-code platform ASCN.AI. Only a graphical dialogue system is required to set up blocks—nodes for parsing, filtering, summarizing, and sending notifications.
The scheme is as follows:
- Trigger: Scheduled via Cron every 15 minutes, hour, or 6 hours.
- Node 1: HTTP Request → Bright Data
A GET request is made to the API to retrieve news, for example, 200 items in JSON format. - Node 2: Logic → Filtering
Here, duplicates and uninteresting topics must be removed (e.g., extract only crypto news to filter out articles about the stock market). - Node 3: AI Agent → OpenAI GPT-4
The filtered selection is passed into a request asking for a summary: "Create 5 key points with sources and dates." - Node 4: Delivery → Telegram Bot
The finished report is sent to a Telegram channel or private messages.
The entire process of launching a notification takes 30 to 60 seconds.
Typical Problems and Solutions
- Rate limits: OpenAI has a limit of 3,500 requests per minute. To process thousands of news items, they need to be broken into batches of 50–100 articles.
- Timeout: Some sites take a long time to respond—set the HTTP request timeout to at least 30 seconds, or the process will fail.
- Error Handling: If Bright Data returns an empty array (site unavailable), the administrator should be notified, and OpenAI processing should be skipped.
- Essential Keys: Keep your API tokens securely hidden in the "Secrets" section of ASCN.AI to prevent leaks.
Use Cases: Examples of Automated News Summaries and Analysis
Case 1: Monitoring Venture Investments in Web3
Situation: An investor monitors funds like a16z, Paradigm, and Binance Labs, spending 2 hours a day manually checking 20+ sources.
Solution: Launched a workflow in ASCN.AI:
- Bright Data parses TechCrunch, CoinDesk, and venture fund Twitter accounts.
- OpenAI filters news regarding new investment rounds.
- A Telegram bot sends a morning digest in the format "Project → Amount → Fund → Brief Description."
Result: Time saved up to 10 minutes a day. Over a month, they discovered three promising projects at the seed stage (Anysphere, LayerZero, Worldcoin) before major media outlets reported them.
Case 2: News Arbitrage on Listings
Situation: A trader learns about a token listing on Telegram, but by the time they reach the terminal, the price has already risen by 15–20%.
Solution: Integration of Bright Data + OpenAI + Exchange API:
- Parsing Binance and Coinbase Telegram channels via Bright Data.
- OpenAI recognizes the "listing announcement" pattern.
- Automatic token purchase via API (limit order at +5% of the current price).
Results: Average trade latency—8 seconds. Over 3 months, 12 successful trades with a 7–12% ROI. PEPE listing on Binance resulted in +28% in just 40 minutes.
Case 3: Risk Monitoring for DeFi Protocols
Situation: A team monitors mentions of their protocol to react quickly to rumors of hacks or bugs.
Solution: A workflow with a trigger firing every 5 minutes:
- Bright Data scans Twitter, Reddit, and Telegram using specified keywords.
- OpenAI analyzes the sentiment of the publications.
- In the case of negative sentiment from authoritative sources (>10K followers), a notification is sent to Slack.
Conclusion: Starting from the fourth month of tracking, they identified 7 threats and twice reacted by debunking fakes within 15 minutes, preventing panic and liquidity outflows.
Benefits of Using Automated News Digests
Manual monitoring is not just reading headlines; it involves cross-checking, selection, analysis, and forming conclusions. An analyst spends 90–120 minutes on one area (e.g., DeFi). An automated digest reduces this time to 5–10 minutes and improves quality, as the system does not tire and does not miss important signals.
| Parameter | Manual Monitoring | Automated Digest |
|---|---|---|
| Processing time for 200 news items | 90–120 minutes | 5–10 minutes |
| Number of sources | 10–15 | 200+ |
| Risk of missing important news | 25–30% | <2% |
| Reaction time | 15–60 minutes | 30–60 seconds |
| Cost (of three analysts) | $9,000/mo | $500–1,000/mo |
Time savings allow for a corresponding amount of work to be performed in the same period it took before automation. This also highlights other parameters showing the level of quality: information processing speed, volume of information processed, probability of missed information, reaction time, and cost of operation.
The difference between manual monitoring and an automated digest is so vast that all parameters could be replaced by one—"Work Value." However, this isn't necessary. It may inspire thoughts on using automation for other types of monitoring or how to improve the quality of automatic monitoring—including by increasing the volume of processed information. Learn to scale monitoring without hiring more people (instead of three analysts in different markets, we run parallel workflows and get summary data across all sectors at once).
The increase in quality is caused by:
- Absence of the Human Factor
By the end of the day, an analyst's attention drops by 40%. AI processes the 100th news item with the same accuracy as the first. - Cross-Verification
GPT skillfully compares information from different sources and flags inconsistencies for review. - Context
The entire history is viewed through the prism of historical context and the consequences of past experiences.
Relevance and Timing of Information Receipt
In crypto trading, a ten-minute delay is already a missed opportunity. For example, at 14:00, news of a token listing appears on an exchange. By 14:10, early participants have already opened positions and secured the first growth. By 14:15, major media outlets publish the material, and the crowd starts buying—but the price has already risen 15–20%. If you received the signal at 14:20, there is practically nothing left to enter: the main move happened without you.
The automated digest works in real-time:
- Trigger fires every 5-15 minutes
Workflows run automatically—even news at 14:02 will be in your Telegram by 14:05 with new analysis. - Prioritization of urgent news
OpenAI tags [URGENT] for critical events—regulatory lawsuits, hacks, and listings. - Instant Notifications
Integration with Telegram, Slack, and Email with signal settings to ensure nothing important is missed.
In practice, the following was recorded: Flash Crash October 11, 2024. Our system noticed a $2.1 billion liquidation on Binance at 02:14 UTC; the signal arrived at 02:16. Users managed to open a short before the main wave, earning 8%–12% in half an hour. Those who had to monitor manually only found out about the 30% market drop after recovery had already begun at 02:45–03:00.
Data quality is maintained by:
- Primary sources—Press releases, company blogs, regulator sites (SEC, CFTC).
- Closed channels—Paid analytical platforms (Messari, Glassnode), private Telegram groups.
- Social signals—Active Twitter accounts and popular Reddit threads.
This coverage provides a distinct advantage over standard RSS aggregators that only collect public feeds, usually with a delay.
Practical Recommendations for Automating News Scraping
Tip number one: define your data volumes and update frequency. If you need to monitor 50–100 sources once a day, simple no-code solutions (Zapier + RSS) will be sufficient. If you intend to cover 200+ sources live, the optimal combination is Bright Data + OpenAI + ASCN.AI.
Setting up Bright Data:
- Register at brightdata.com, choose the Scraping Browser or Ready-Made Datasets plan (the latter is suitable).
- Go to the Datasets section and find the "News Sites" or "Social Media" template.
- Specify the domains for data parsing (CoinDesk, Bloomberg, TechCrunch, etc.).
- Set the frequency for fetching data—from 15 minutes to 6 hours.
- Obtain your API key and endpoint for requests.
Setting up OpenAI:
- Create an account at platform.openai.com.
- Generate an API key via "API Keys."
- Choose the GPT-4 Turbo model.
- Set a monthly spending limit—for example, $100—to avoid unexpected charges.
Setting up ASCN.AI:
- Go to Workflows → Create New.
- Add a Cron trigger with a schedule—for example, every 15 minutes.
- Add an HTTP Request node with the parameter
{{brightdata_api_key}}. - Add an AI Agent (OpenAI) node with the prompt:
Model: GPT-4 Turbo; Prompt: "Summarize these articles in 5 bullet points..."; Input: {{$node["BrightData"].json}} - Add a Telegram Bot node to send notifications.
- Save the workflow and activate it.
Setup Errors
- Incorrect data format
Bright Data returns a JSON array, while OpenAI expects a string. Solution: use a Code node for conversion. - Exceeding OpenAI limits
Sending 500 or more news items in one request exceeds the token limit. Break data into groups of 50–100 articles. - Vague requests
If GPT provides a blurry summary, clarify the output format, add mandatory elements, and provide an example.
Data Requirements and Ethical Compliance
Parsing is regulated by laws (GDPR, CCPA) and site rules. Violations lead to blocks, fines up to €20M, and lawsuits. Here is what is important to know:
- robots.txt—Check which sections are allowed for parsing. Bright Data does this automatically.
- Request frequency limits—No more than 10–20 requests per second to a single site to avoid creating a DDoS effect.
- Personal data—Special software is needed to remove names, emails, and phone numbers before saving or publishing them. OpenAI tools can help with this.
- Copyright—Headlines and summaries up to 200 characters with links are generally allowed, but using full text publicly is restricted.
- Commercial use—If you want to profit by selling news digests, be sure to read the licensing agreements of the sources.
For safe parsing: Work with public sources. Do not enter closed sections without permission. Add instructions to the OpenAI prompt to filter personal data. Store your keys in secure managers (ASCN.AI Secrets, AWS Secrets Manager). Monitor request logs for errors and blocks (403, 429).
Frequently Asked Questions (FAQ)
What is Bright Data and why use it?
Bright Data is the largest provider of proxy infrastructure and ready-made scrapers. It covers 72 million IPs in 195 countries. Why choose it?
- Ready-made templates: No need to write code; choose a scenario and a list of domains.
- Web Unlocker: Automatic bypassing of Cloudflare, reCAPTCHA, and other protections with a 99.2% success rate.
- Residential Proxies: Traffic looks like it’s coming from a real user rather than a data center, reducing block risks.
- Consistency: 99.9% uptime even with 50,000+ concurrent requests.
Disadvantages: High price (from $500 monthly) and a complex interface for beginners. Suitable for established companies and experienced users.
What are the limitations of OpenAI GPT for working with news?
- Context limit—Up to 128,000 tokens per request for GPT-4 Turbo, but with 500+ news items, data must be partitioned.
- Knowledge cutoff: The model was trained on information up to October 2023 and doesn't know about fresh events unless they are passed entirely in the prompt string.
- Hallucinations: It sometimes invents facts or misreports numbers. Important detail—verify data separately or formulate the prompt so that the AI doesn't speculate on unknowns.
- Cannot verify sources: It cannot click through hyperlinks for verification, so it’s better to use Bright Data as the primary source collector.
- Cost: GPT-4 Turbo: ~$0.01 per 1K input tokens and ~$0.03 per 1K output tokens.
- Dependence on the prompt: If the request is poor, the answer will be vague or incomplete.
How is data quality and reliability ensured?
- Choosing authoritative sources—Bloomberg, Reuters, CoinDesk. Get rid of unverified blogs and anonymous channels.
- Cross-verification: Compare information from different sources for contradictions.
- Avoid outdated news: Filter out materials older than 24 hours, especially in trading.
- Monitor logs and parsing success: If the site structure changes and success drops below 95%, the parser must be rebuilt.
- Add disclaimers—State that the information is automated and requires verification.
Conclusion and Future Outlook
The growth rate of the news automation market is 28% per year. More segments of the economy are adopting AI news aggregation.
- Transition from RSS to AI: RSS is outdated—slow and lacks context. AI aggregation personalizes digests.
- Multimodality: GPT-4V analyzes images, infographics, and videos alongside text.
- Predictive Analytics: AI predicts the market impact of news with real probability.
- Hyper-personalization: Digests adapt to the specific individual—trader, investor, or marketer.
Whoever adopts these technologies first will gain a 6–12 month competitive advantage.
The near future of AI and web scraping in the news industry is full automation of newsrooms. AI will handle the routine; investigation and deep analysis will remain with humans. Fighting disinformation: AI will learn to recognize fakes with over 95% accuracy. Integration with blockchain oracles: smart contracts will be able to react automatically to news from verified sources. Voice and video digests—automatic generation of podcasts and videos from news instead of text summaries.
In summary: informational advantage today is the speed of automation and the quality of AI analysis. Those who connect Bright Data + OpenAI first will win tens of minutes. And in trading, those ten minutes can turn into significant profit.
How ASCN.AI Helps You Escape the Routine of News Parsing
ASCN.AI is a no-code automation platform with AI agents and ready-made workflows. In the News domain, it solves key problems:
- Automated data collection. Ready-made integrations with Bright Data, Telegram, and RSS; the entire system is built without programming. Launch and processing take 30–60 seconds.
- Monetization through subscription—an additional opportunity: you can set up a digest for your niche and sell it to your clients. For example, an arbitrageur using ASCN.AI earned $2,000 a month selling token listing signals.
- Personal AI Analyst: Implement capabilities to answer questions in 10 seconds—"Why did token X fall?", "Who invested in the project?".
