- Русский
- English
Automate audio/video transcription in any language with the new ElevenLabs model
ASCN.AI automates audio and video transcription using ElevenLabs Scribe v2, achieving a 2.3% word error rate. The pipeline integrates directly with Google Drive and Dropbox to deliver professional transcripts in 99+ languages with speaker identification and word-level timestamps.

ASCN.AI automates audio and video transcription using ElevenLabs Scribe v2, the most accurate speech-to-text model in 2026 benchmarks (2.3% WER). Files dropped into Google Drive or Dropbox are automatically transcribed in 99+ languages with speaker identification, word-level timestamps, and SRT/VTT output — pipeline deployed in 48 hours, no developer needed.
Quick Facts
- Languages supported: 99+ with automatic language detection (includes low-resource languages)
- ElevenLabs Scribe pricing: $0.40/hour of audio via API ($0.0067/minute)
- Speaker diarization: Up to 32 unique speakers identified and tagged automatically
- Output formats: SRT, VTT, plain text, JSON with word-level timestamps
- Deployment time: ASCN.AI deploys the full pipeline in 48 hours
- Cost savings vs. human transcription: 70–80% reduction in transcription costs
- Connect your storage: Link Google Drive or Dropbox as the file source in ASCN.AI.
- Drop an audio or video file into the monitored folder.
- ASCN.AI triggers the workflow and sends the file to ElevenLabs Scribe via API.
- Scribe transcribes in 99+ languages with speaker names and timestamps.
- The transcript lands in Notion, Google Docs, or your database automatically.
The process of using ASCN.AI is so simple; drop your file in the folder. That’s it! Within a matter of minutes after you drop the audio or video file in there, you will have the clean transcripts ready for review in your Notion or Google Docs workspace complete with the speaker names, word-level timestamps, and subtitle files. You will not need to do any clicks, upload any files manually, or will you need to wait three days for a transcription service to transcribe your file at $1.50 per minute.
The pipeline that ASCN.AI builds is composed of two parts; we manage the automation logic and ElevenLabs Scribe manages the transcription. According to research from Sonix (2026), 62% of professional workers save about four hours a week with the use of automated transcription, or almost one full month of time reclaimed each year. You receive an operational, multilingual audio transcription automation – which is available live within only 48 hours – and supports over 99 languages, allowing for built-in speaker diarization from the onset.
There is no developer needed on your end. None.
How Automatic Transcription Works and Why Traditional Manual Transcription Makes No Sense
ASCN.AI's automated transcription services convert audio / video files into a structured text, hands-free. Input files will be added to a monitored folder (such as a Google Drive, Dropbox or direct upload endpoint), and after triggering the workflow, ElevenLabs Scribe will process the file and email you the finished transcript – all with no human action.
The financial side is pretty simple; the cost of a typical 60-minute podcast episode that would have taken 3-4 hours to transcribe by a human and cost between $90-$240 to do now takes 5-7 minutes and costs about $0.40. That's a 70% to 80% decrease in your cost, according to data in the industry. The AI transcription billing market is growing at 15.6% CAGR and is projected to reach $19.2 billion by 2034. This is not an experimental niche product.
The folder-to-transcript process: zero clicks, zero waiting
When you record an in-person meeting, export a podcast episode or receive a video interview, you simply add the file to your designated folder. Everything else will happen automatically. ASCN.AI will be watching the folder 24/7 and when they detect a new file, they will start the transcription workflow. You will receive a notice when the transcript is complete. This is particularly significant for teams generating high-volume audio content. The manual uploading and waiting process will fall apart when done at large scale, whereas folder-drop automation will scale without issue.
What you get: speaker labels, timestamps, SRT subtitles, clean text
With ASCN.AI you get speaker designations, timestamps, subtitles in SRT format, and a clean text file. Each audio file generates transcripts with the following:
- Plain text – a clean and readable transcript for your documents, CRM entries, and blog posts
- Speaker designations – automatic identification of up to 32 unique speakers labeled "Speaker 1", "Speaker 2", etc.
- Timestamps at the word level – Each word has a timestamp corresponding to its time of occurrence in the audio
- SRT and VTT files – Subtitles in SRT and VTT formats compatible with YouTube, video editors, and HTML5 players
- JSON package – Contains both the structuring and tagging of all entities, audio events, speaker information, etc.
Supported inputs: MP3, MP4, WAV, MOV, M4A and more
You can use various audio and video input formats with ASCN.AI. For audio, you can use: MP3, WAV, M4A, AAC, FLAC, OGG; and for video, you can use MP4, MOV, AVI, MKV. ASCN.AI will extract your audio track from your video automatically and you won’t have to do anything to convert before uploading.
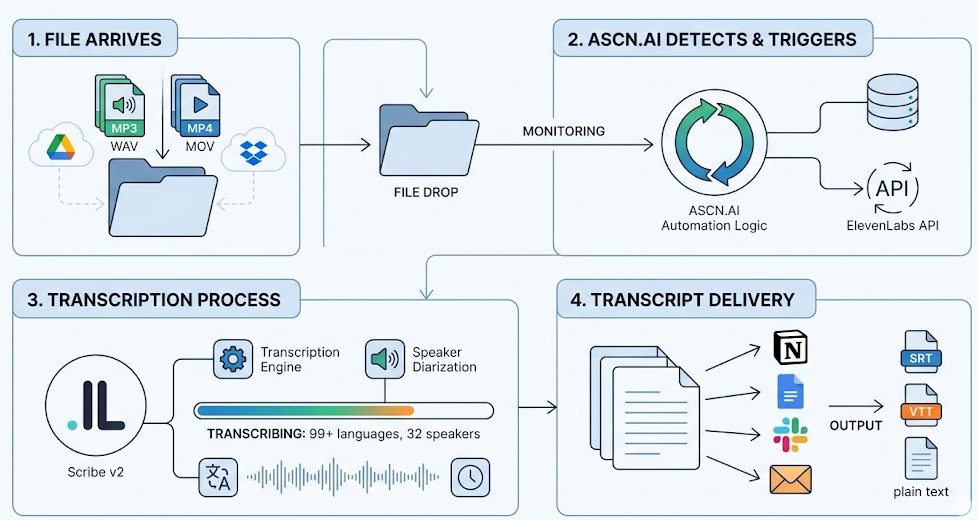
How ASCN.AI Automates Your Transcription (Step-by-Step)
There are four steps in the overall ASCN.AI Transcription Automation process: File arrives, Workflow Triggered, ElevenLabs audio transcription processed, and Transcript delivery. Each step is entirely automated after the first folder has been established. There is no user interaction needed beyond setting up.
Step 1 — File lands in Google Drive or Dropbox
Use Google Drive or Dropbox to create a folder to act as your intake point. ASCN.AI sets up a folder monitoring trigger (to watch for new event creation) and monitors for new files being created and whenever you create, move, or copy files to the folder, the trigger will fire within seconds regardless of event time.
Native integration is provided especially for Google Drive and Dropbox which both offer APIs with official polling and webhook methods. Additionally, if your organization uses self-hosted file storage systems like SharePoint, or others, these can be added to ASCN.AI's integrations.
Step 2 — ASCN.AI detects the file and triggers the pipeline
The Workflow Engine will then receive the file's metadata, download its content, and call ElevenLabs' API to input the data for transcription. Files unsupported by ElevenLabs will be flagged by the engine (to avoid use of credits) and an error will occur when trying to send the unsupported file to the API instead of failing silently.
At this point in the workflow, Configuration Options include: Auto Detection / Manual Language Specification (Language Detection), Speaker Diarization Check (Enabled / Not Enabled), Keyword List Injection (Input), Output Type Specification (Text, Audio, or Both). The above options will only be configured during the deployment of ASCN.AI.
Step 3 — ElevenLabs Scribe API processes audio and video
ASCN.AI will call the ElevenLabs Speech-to-Text Scribe v2.0 API to process the audio and video data. It is estimated that transcription will occur between 3 and 8 times faster than real time, i.e. a 60 minute video/audio will print out a transcript in approximately 7 to 20 minutes after initiation of the transcription request. The response from ElevenLabs API will include the entire transcript, Speaker Identified Segments, timestamps for each word identified, and entity detections as well as audio events.
In the current version of Artificial Analysis AA-WER Benchmark (Version 2.0) (2026), Scribe v2.0 obtained a word error rate of 2.3% which was the best performance of any of the three models tested including Google Gemini 3 Pro (2.9%) and OpenAI Whisper Large v3.0 (4.2%).
Step 4 — Transcript delivered to Notion, Google Docs, or your database
ASCN.AI will transmit the completed transcription to the user's chosen output – Notion, Google Docs, or a database, etc. Our current workflows include:
- Notion: A new page created in a specified database, with each speaker's name listed as a property
- Google Docs: A new document created in a particular folder, formatted to be readable
- Google Sheets / Atrium: A row is created with metadata (filename, length, language, date)
- Email or Slack: A notification that has either a link or an attached transcript
- Custom API Endpoint: To POST a JSON payload to your system
Webhook notifications and error handling
Transcription completion will trigger either a Slack, email or an HTTP webhook notification. If the transcriptions fail, an alert indicating what caused it to fail along with the corresponding file path will be sent out. Retries will automatically occur for any transient API failure maximum of 3 times prior to escalation to a notification.
ElevenLabs Scribe v2 — Accuracy, Languages, and Key Features
As of 2026, ElevenLabs Scribe v2 is the most accurate speech-to-text system as per independent benchmarks (2.3% Word Error Rate (WER) for 99+ languages), as well as having Speaker Diarization at 32 Speakers, Word Level Timestamps & Keyterm Prompting for Specialized Vocabulary.
Accuracy benchmarks: Scribe v2 vs. Whisper, Gemini, AssemblyAI
| Model | WER (AA-WER v2.0, 2026) | Notes |
|---|---|---|
| ElevenLabs Scribe v2 | 2.3% | Industry #1 overall |
| Google Gemini 3 Pro | 2.9% | |
| Mistral Voxtral Small | 3.0% | New 2026 |
| Google Gemini 2.5 Pro | 3.1% | |
| OpenAI Whisper Large v3 | 4.2% | Open Source |
| AssemblyAI Universal v3 Pro | 2.3% (agent-talk) | 3rd place in AA-AgentTalk |
For 10,000 words of transcripts: Scribe v2 - 230 errors, Whisper - 420 errors. In legal or compliance documentation, the discrepancy between Scribe's accuracy and other systems has major significance. Both produce acceptable transcripts for casual podcasting. However, when automating production, accuracy compounds for proper reporting to clients.
99+ languages — including low-resource and regional ones
Scribe supports 99 languages for transcription in 2026, with good results even for languages that are poorly handled by larger models. Comparative benchmark WERs for Scribe and Whisper v3 against the same audio file show a 3x proportional lower error rate: 3.1% for English (FLEURS), 1.3% for Italian, and 2.4% for Indonesian versus 7.7% for Whisper v3. For other underserved languages such as Serbian and Mongolian, Scribe provides comparable accuracy while other systems do not.
Scribe automatically detects the language of recorded audio. You do not need to specify a language before submitting your audio for transcription. There is an option available to specify a language when submitting mixed-language audio for transcription.
Keyterm prompting for specialized vocabulary
Standard transcription systems struggle with transcribing rare proper nouns, brand names, legal jargon, and specialized vocabulary. With Scribe v2, you can provide up to 1,000 keyterms so the model prioritizes their transcription. Examples include case names, drug names, product names, and the names of guests — so they are transcribed accurately instead of phonetically approximated. ASCN.AI will create your keyterm list upon deployment.
No Verbatim mode — clean transcripts from natural speech
By using Scribe's No Verbatim transcription mode, filler words like "um," "uh," and repeated phrases, and stutters will be removed automatically. This provides a clean, readable transcript of casual speech and informal conversation. This feature is particularly helpful for sales calls and interviews. In Scribe v2, this is done automatically, whereas older versions of Scribe required additional post-processing to remove filler words.
Dynamic audio tagging
Scribe v2 tags dynamic audio events with each transcription, such as laughter, applause, music, background noise, and extended silences. This tagging provides context to the transcribed text; for example, knowing that there was laughter at the same time that the speaker was speaking; or hearing a long silence following a long-winded speaker. Video editors use dynamic audio tagging to locate points to cut without having to scrub through the video.
Speaker Diarization, Timestamps, and Output Formats
Diarization for speaker identification and timestamping in ElevenLabs Scribe v2 can identify and label recordings with a maximum of 32 different speakers and provides timestamps for every unique word recorded. The output can be generated in four formats: SRT, VTT, plain text, and JSON.
Who said what — automatic speaker identification and labeling
Diarization for a maximum of 32 different speakers in an audio recording is handled with Scribe v2. Segment output is automatically labeled by speaker so that it can be utilized for podcast interview transcripts, multi-sound sales call transcripts, depositions, team meeting transcripts, etc. A useful transcription demonstrates the distinctions between different speakers in a text; whereas, a bulk transcribed document does not showcase these variations.
Speaker labels will be automatically applied. In those instances where an identifier (number) does not suffice, ASCN.AI offers a post-processing procedure to convert the Speaker ID (number) to a Client's name if a list of participants exists.
Word-level and segment-level timestamps
There will be a start (in milliseconds) and end (in milliseconds) timestamp for every word created. This timing allows for many additional capabilities, including video editing (e.g. linking a specific word to its location in the video), extraction of specific segments for determinate phrases using time, subtitle synchronizing (subtitle generation from Word level timestamps) and QA processing (finding any low confidence segments for manual review).
Export formats: SRT, VTT, plain text, JSON
All output formats will be configured depending on your downstream usage i.e. SRT for YouTube and video editors - VTT format will work well with HTML5 players - plain text will work well for blogs/CRM notes - JSON will work for database storage or AI applications. Each of these formats can run simultaneously when provided as a single API call.
Sensitive information redaction
Sensitive data will be determined and taken out of the transcript via the Scribe’s ability to scan and remove personal information such as names, addresses, financial information, or health related data before the transcript is moved to your storage. The ElevenLabs system is compliant to SOC 2, HIPAA, and GDPR including having an available option for EU data residency and a Zero Retention mode for stricter data controls.
Who Uses Automated Audio Transcription — and How
Automated audio transcription is used for audio content by multiple audiences/professions including podcasters, legal/compliance teams, sales teams, electronic learning creators, and video producers. Each use case has a distinct output destination and a different set of downstream workflows that ASCN.AI can extend.
Podcasters: episode transcripts, SEO, show notes
Podcasters will see a increase of 7.2x in organic traffic to episode pages that include an episode transcript compared to just audio. One episode transcript can generate 3–5 blog posts and 20+ social media posts. For example, a weekly podcast can now be produced without any delays due to the transcription bottleneck. The ASCN.AI workflow for a podcaster is: Upload episode to Google Drive; 10 minutes later have transcript available in Notion for show notes and to draft blog.
Legal and compliance teams: accurate records, call logs
Legal/Compliance obtain accurate records of their business activities such as phone call logs using automatically transcribed recordings. For example, a deposition of 2 hours with 2% word error rate (roughly 250 errors) would be acceptable for review but not as primary documentation without some quality assurance. Accurate transcription of various legal terms can be achieved through Scribe v2 accuracy level and entity redaction capability provides preliminary evidence to be used in court of law.
Sales teams: CRM-ready call summaries
Sales teams have all calls automatically added to their relevant transcription pipeline. All speaker labels are applied by ASCN.AI during output and provided into your customer relationship manager system. ASCN.AI has a secondary workflow that provides an extracted call summary that identifies action items and next steps. All information on completed calls created with transcript will allow you to find record by your customer relationship manager (CRM).
E-learning creators: lectures and webinars into course notes
A one hour long video lecture is automatically converted to three product categories: A fully timestamped transcription (text) document; A chapter-based summary outlining the overall topic with each section color-coded (within the text); and a handout that is downloadable for future reference. Dynamic audio tagging technology is also being utilized to create an automatic chapter-based navigational system for easy access to relevant segments of long videos.
Video producers: captions and subtitles for social media
The absence of captions on video will decrease engagement rates. Videos that auto-play with sound off on platforms have significantly lower viewership than those that are captioned. ElevenLabs' Scribe platform automates this process - simply upload your video, and the output will include the corresponding SRT/VTT files that are attached to your original media file enabling you to plug into your YouTube SEO or edit according to your needs.
Cost and Pricing — ElevenLabs Scribe vs. Alternatives
The price to use the ElevenLabs Scribe API is $0.40 USD/hr of audio; therefore, in 2026, ElevenLabs Scribe API will provide the highest level of accuracy and second least expensive option available today for automated transcription services. When compared to manually produced transcription services, using ElevenLabs' ASCN.AI pipeline process will yield a 70-80% cost savings.
| Option | Cost per hour | WER / Accuracy | Turnaround |
|---|---|---|---|
| Human transcription service | $90–$240 | ~1% | 24–72 hours |
| OpenAI Whisper API | ~$0.36 | 4.2% WER | Minutes |
| Google Speech-to-Text | $0.96–$1.44 | ~2.9% WER | Minutes |
| AssemblyAI | $1.20 | ~2.3% WER | Minutes |
| ElevenLabs Scribe v2 | $0.40/hour | 2.3% WER | Minutes |
According to independent testing, ElevenLabs Scribe ranks #1 among the examined competitors on accuracy at $0.40 USD/hr. ElevenLabs rates are approximately 1/2 of the cost associated with employing humans to transcribe audio at $1.50 - $4.00 per audio minute (200% - 600% more expensive), while OpenAI Whisper has an identical unit price but produces almost twice as many errors per 10,000 words compared to ElevenLabs.
Pricing note: Check for accurate current pricing at: elevenlabs.io/pricing/api. Comparison dataset from Third Party Independent Study - Artificial Analysis (2026).
How ASCN.AI service pricing works
ASCN.AI will assess the service fees associated with the setup and maintenance of automated services only; there will not be a charge for transcribing digital audio. You will make payments to ElevenLabs for access to their API through your account. The amount you will pay does not include ASCN.AI's markup above the per-transcript cost; therefore, your total cost will match what you pay to ElevenLabs. The more you use the API, the better any user will be able to get value from it. Please contact ASCN.AI to learn more about tiers of service.
ASCN.AI Deployment — Working Pipeline in 48 Hours
ASCN.AI can deploy a fully configured, end-to-end automated transcription pipeline within 48 hours. No development work is required from your organization, and ASCN.AI will take care of setting up all the required software for the API. This means that ASCN.AI will configure folder monitoring (Google Drive or Dropbox), configure the ElevenLabs Scribe v2, route the output to the destination of your choice, handle all errors, provide webhooks notifications, and test the system before handing it to you.
What's included in the full configuration
- Configure Folder Monitoring for either Google Drive or Dropbox
- Connect to ElevenLabs API and configure ElevenLabs Scribe v2
- Configure Speaker Diarization and Language Setting
- Create Keyterm List and Keyterm List by Domain
- Route Output to Destination
- Set-Up Error Detection and Retry
- Send Webhook Notifications (Slack, Email, or HTTP)
- Create Sample Test using your actual files before handing-over
- Provide documentation on how the system will work and schedule a Hand-Off Call
What you need to provide
- Create an ElevenLabs Account (Free Tier for Setup and Paid Tier for API Usage)
- Provide Access to your File Storage (Provide Google Drive/Dropbox Permissions)
- Provide Access to your Output Destination (Notion Workspace, Google Account, etc.)
- Provide ASCN.AI with a Test Audio or Video File
- Provide Keyterm List (Required for Specialized Domains)
Ongoing support and adjustments
After Deployment, ASCN.AI takes care of any issues related to workflow(s), adjusting the Pipeline or any changes you may decide to make, and/or formatting changes you may decide to make. If you need to add an output destination, change the Keyterm List, change the trigger folder, or change to a second Language Track, you will not need to get involved in the pipeline in any way.
Scribe v2 Realtime — for live transcription use cases
Scribe v2 Realtime is a system for completing batch transcriptions in bulk through a file-to-transcription process. As a system for completing real-time transcription (e.g., voice agents, real-time captioning, and call centre monitoring), Scribe v2 Realtime has a latency of less than 150ms. This same service can also be used through the ASCN.AI pipeline, with different configurations but a commitment to a 48-hour turnaround.
Frequently Asked Questions
What formats does ElevenLabs Scribe (via ASCN.AI) support for automated transcription of audio and video?
The Scribe v2 (via ASCN.AI) platform can transcribe all defined audio formats (MP3, WAV, M4A, AAC, FLAC, OGG) and video formats (MP4, MOV, AVI, MKV). The system will automatically extract audio from video files as a system function so that you do not have to manually convert your video audio file to the needed audio format. Audio files may be uploaded to Google Drive or Dropbox folder or through the API.
How can I compare the accuracy of ElevenLabs Scribe to OpenAI's Whisper app?
Using the Artificial Analysis AA-WER v2.0 Benchmark (December 2026), ElevenLabs Scribe v2 achieved a 2.3% word error rate compared to the 4.2% word error rate of the OpenAI Whisper Large v3, which is almost two times more accurate. For example, if I had a ten thousand word transcript, ElevenLabs Scribe would contain approximately 230 errors and OpenAI Whisper would contain approximately 420 errors. Therefore, the difference between the two products is especially important for legal transcription or for transcription of medical records.
Can ElevenLabs Scribe recognize multiple speakers in one audio recording?
Yes, ElevenLabs Scribe can identify each of up to 32 speakers in each audio file they transcribe with word-level timestamps and each segment of recorded material will have been identified as relaying information from them (e.g., speaker 1, speaker 2, etc). ASCN.AI offers a feature that allows users to connect speaker IDs with real participants' names for recurring meetings after they have finished being recorded.
How much does it cost for automatic transcriptions per hour of audio from ElevenLabs Scribe?
In 2026, the cost of the ElevenLabs Scribe v2 through API is $0.40 per hour of audio input (approx. $0.0067 per minute), compared to approximately $90-240 per hour for human transcription services and approximately $0.96-1.44 per hour for Google Speech-to-Text. ASCN.AI has no markup on the ElevenLabs API; therefore, pricing will be the same for you as it is for ASCN.AI clients. Please check elevenlabs.io/pricing/api for accurate pricing.
How long does it take to implement an automatic transcription pipeline?
After 48 hours of configuration, ASCN.AI prepares a fully functional automated transcription pipeline, including folder monitoring (Google Drive or Dropbox), ElevenLabs Scribe API configuration v2, routing of outputs to your specific destination, error handling, webhook notifications, and testing with your files. No developer on your part will be needed.
Does ElevenLabs Scribe support all languages, even minority languages?
As of 2026, ElevenLabs Scribe v2 has over 99 languages that are detected automatically. The quality of automatic transcription of many underserved languages is very high (2.4% WER for Indonesian compared to 7.7% for Whisper for the same audio). Serbian, Mongolian, and similar regional languages can also be detected, and very often, transcription is not possible by many competing products. Automatic language detection is available with the option to override.
What are the output formats for this transcription pipeline?
The ASCN.AI transcription pipeline produces SRT formatted subtitle files for YouTube and other video editing programs, VTT files for HTML5 players, plain text files for documentation and/or CRM entries, and JSON with all the metadata associated with each word including timestamping to the word level, speaker identification, entity coding, and audio event identification. A single API call can generate multiple file outputs, e.g., producing SRT for a video project folder and plain text for a Notion database simultaneously.
Are the transcriptions of the recordings compliant with HIPAA and GDPR?
All of the ElevenLabs infrastructures are SOC 2, HIPAA, and GDPR compliant. For customers with strict data sovereignty needs, the EU residency and Zero Retention Modes can be used. The Scribe v2 also provides entity redaction functionality, which automatically removes sensitive information (e.g., name, address, health-related) prior to being stored in your systems.
