- Русский
- English
How to Build an AI Voice Assistant: Building from Scratch with GPT and TTS

Voice assistants are evolving at a staggering pace. Companies that previously spent months searching for and training operators are now deploying bots over a single weekend. Such solutions save thousands of hours of routine work. We’ve been through this ourselves — from indexing blockchain nodes and automating crypto-arbitrage to building an entire ecosystem of products that operate almost without programmers. Now, I’m ready to share how you can build your own voice assistant from scratch: which technologies to choose, how to avoid going broke, and how to truly save time.
“We spent two years indexing nodes and developing sentiment models to provide answers based on real-time blockchain data rather than simple web searches. GPT and other LLM models do not work directly with the blockchain, which makes our approach unique in crypto-analytics.”
Introduction to Voice AI Assistants
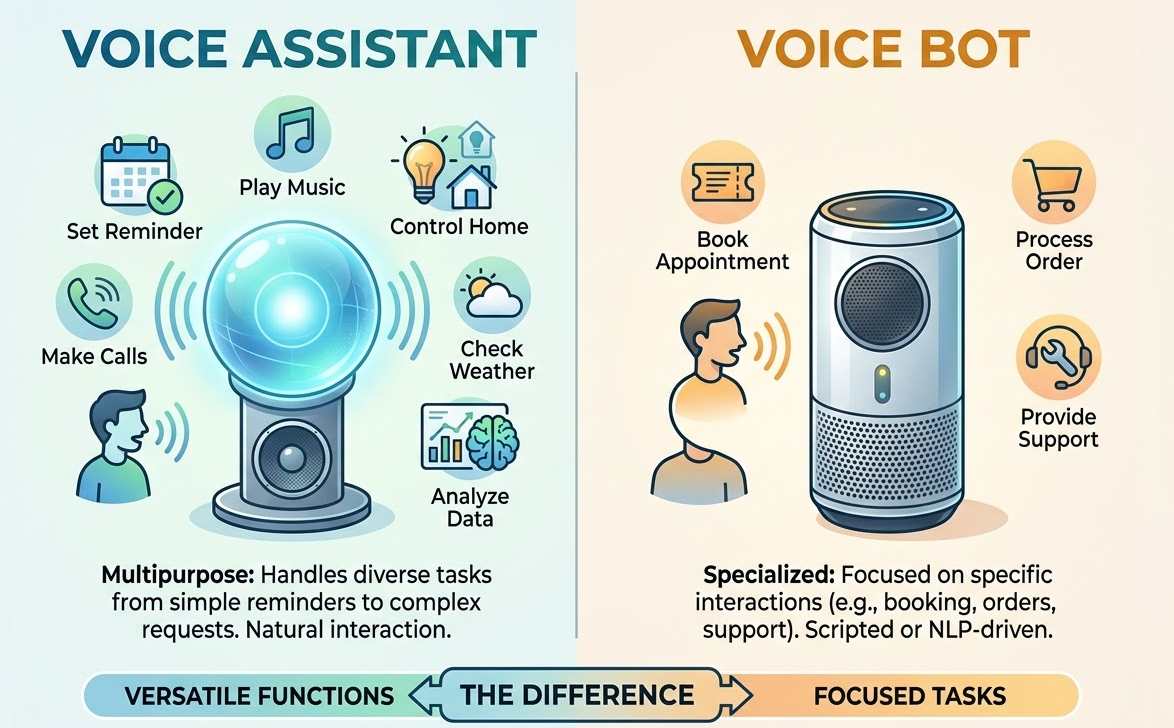
A voice assistant is a program that listens to you, understands you via NLP, recognizes speech through ASR, and responds with a voice via TTS. It performs functions ranging from simple reminders to complex analytics.
A voice bot is a specialized version. It is tailored to a specific task: taking orders, technical support, or booking. It operates based on scripts or a combination of scripts and NLP.
The difference is simple. An assistant acting as a bank employee is capable, surprisingly enough, of answering a wide variety of requests: checking balances, transferring money, or providing loan consultations. A bot for the same bank might only accept loan applications. And that’s it.
At ASCN.AI, our voice agents automate news parsing, token analysis, and report generation. A client asks a question via voice on Telegram — the agent extracts data from on-chain nodes, news aggregators, and social media, providing a structured response within 10 seconds. This saves an analyst up to 40 man-hours of manual labor per month.
Key Technologies: NLP, ASR, TTS, and Voice Automation
NLP (Natural Language Processing) — these are the most advanced algorithms that allow the system to understand human language. For example, GPT-4 is built on transformers: it analyzes all words simultaneously rather than sequentially. Therefore, it can process multi-step queries and generate relevant answers.
ASR (Automatic Speech Recognition) — converting sound to text. Popular systems include OpenAI Whisper, Google Cloud Speech-to-Text, and Yandex SpeechKit. Whisper was trained on 680,000 hours of audio in 97 languages; its recognition accuracy exceeds 90% even in noisy environments (OpenAI, 2022).
TTS (Text-To-Speech) — converting text to speech. The latest models (ElevenLabs, Google Cloud TTS, Amazon Polly) reproduce human-like voices with proper intonation and pauses. One of the current trends — voice cloning from a 10-minute recording — allows for the creation of personalized assistants.
Voice Automation combines all components: ASR listens, NLP makes decisions, and TTS responds — all without operator involvement. In short, such bots exist in call centers; they take on the customer's problem, find the answer using GPT, speak it to the customer, and save the data in a CRM.
| Technology | Task | Example Systems | Accuracy / Quality |
|---|---|---|---|
| ASR | Speech Recognition | Whisper, Google STT, Yandex SpeechKit | 90-95% accuracy |
| NLP | Text Understanding | GPT-4, Claude, LLaMA | Context up to 128k tokens |
| TTS | Speech Synthesis | ElevenLabs, Google TTS, Amazon Polly | Naturalness 4.5/5 |
| Voice Automation | Full Processing Cycle | ASCN.AI, n8n + GPT | Reduction in time up to 70% |
As a technological foundation, ASCN.AI utilizes several tools: Whisper for recognition, GPT-4 for generating responses, and ElevenLabs for voicing the results. A Telegram user asks: “Why did the XYZ token price increase?” — the agent gathers information, pulls data from on-chain nodes, scans Telegram channels, and forms a voice response based on a set of queries in just 30 seconds. This replaces 20–30 minutes of manual searching.
The Structure of an AI Voice Assistant
A voice assistant consists of three modules, each performing its sequential task:
- ASR — takes audio input (WAV, MP3, Opus) and converts it into text by recognizing speech. Whisper provides a result with 92–95% accuracy in quiet environments and about 80–85% in noise.
- The next module is NLP — it analyzes the text, identifies intent, extracts entities (dates, values, names), and creates a response. For instance, GPT-4 supports a context window of up to 128,000 tokens (about 100,000 words), allowing for long-running dialogues.
- TTS — converts text back into audio with natural voice quality, intonations, and pauses. ElevenLabs can synthesize a phrase of 15–20 words in 1–2 seconds.
The entire process typically takes between 5 and 15 seconds, depending on API load and query complexity.
The workflow is as follows:
- The user speaks — ASR listens.
- ASR converts audio to text and sends the task to the NLP.
- The NLP generates a response and sends it to the TTS.
- TTS generates the audio response and sends it to the user.
A query like “Give me the sentiment for Bitcoin over the last 24 hours” is processed in 10 seconds instead of 30–40 minutes of an analyst's manual work.
Overview of GPT and Its Role in Voice Bots
GPT (Generative Pre-trained Transformer) is a language model trained on billions of texts. It is capable of creating coherent text while understanding the context of the query.
In voice bots, GPT performs several functions:
- Maintains dialogue context.
- Processes complex multi-step requests by breaking them into sub-tasks.
- Integrates with external systems via Function Calling or plugins — gathering the latest news, on-chain data, and forming clear reports.
Examples:
- Tech Support: The bot understands the client's question, finds the answer in the knowledge base, responds via voice, or transfers to an operator if it cannot help.
- Analytics: Traders receive insights via Telegram regarding "whale" movements based on on-chain data, formulated by GPT and voiced via TTS.
- Voice CRM: A meeting recording is converted into a structured report that is automatically uploaded to the system.
TTS Speech Synthesis for the Computing Assistant
Modern TTS systems based on neural networks (WaveNet, Tacotron, VITS) produce speech that is almost indistinguishable from a human. Text undergoes phonemic breakdown, is analyzed for intonation parameters, and the sound wave is synthesized.
| Platform | Quality | Synthesis Speed | Languages | Cost | Voice Cloning |
|---|---|---|---|---|---|
| ElevenLabs | 4.7/5 | 1-2 sec per sentence | 29 languages | $5–99/mo | Yes, via 10 min recording |
| Google Cloud TTS | 4.3/5 | 1–3 sec | 40+ | $4 per 1M characters | No |
| Amazon Polly | 4.0/5 | 2–4 sec | 30+ | $4 per 1M characters | No |
| Yandex SpeechKit | 4.2/5 (Russian) | 1–2 sec | 3 | ₽80 per hour of audio | No |
The choice depends on the project. For a project in Russian, Yandex SpeechKit or ElevenLabs is suitable. For multilingual tasks, Google Cloud TTS or ElevenLabs is preferred. If voice personalization is required, ElevenLabs with its cloning feature is the only option. At ASCN.AI, we use ElevenLabs to voice analytical reports with natural intonation.
Practical Guide to Creating Your Voice Assistant
Before creating an assistant, you must address three tasks: speech recognition (ASR), response generation (NLP), and speech synthesis (TTS). You can use separate tools or ready-made stacks.
Basic options:
- OpenAI: Whisper for ASR (open-source, API $0.006/min), GPT-4 Turbo for NLP (up to 128k tokens, $0.01/1k input and $0.03/1k output), OpenAI TTS ($15/1M characters). Whisper can be self-hosted.
- Google Cloud: Speech-to-Text (ASR, 90–94% accuracy, $0.016–0.06/min), Dialogflow CX for NLP ($0.007/request), Text-to-Speech ($4–16/1M characters).
- Yandex SpeechKit: 92–95% accuracy for Russian, ₽80/hour of audio, integration with Yandex GPT (beta), natural Russian voice.
Recommendations for these tasks are as follows:
- If on a tight budget: Russian project + Yandex SpeechKit (ASR + TTS) + OpenAI GPT-4 (NLP).
- If multilingual solutions are needed: Google Cloud.
- If premium quality and extreme flexibility are required: Whisper self-hosted + GPT-4 + ElevenLabs.
In the case of ASCN.AI, the average query processing time is 10 seconds, with a cost of approximately $0.05 — $0.08 per question.
Integrating GPT with Synthesis and Recognition Systems
The process can be structured as a pipeline: Audio → ASR → Text → GPT → Response → TTS → Audio → User.
A simple Python example using the OpenAI API:
import openai
openai.api_key = "YOUR_API_KEY"
# Speech recognition
audio_file = open("user_voice.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
user_text = transcript["text"]
# Response generation
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "You are a voice assistant."},
{"role": "user", "content": user_text}
]
)
assistant_text = response["choices"][0]["message"]["content"]
# Speech synthesis
tts_response = openai.Audio.create_speech(
model="tts-1",
voice="alloy",
input=assistant_text
)
with open("assistant_voice.mp3", "wb") as f:
f.write(tts_response["audio"])
For those not interested in programming, there are no-code services like ASCN.AI or n8n — where a ready-made workflow of blocks (Telegram, Whisper ASR, GPT-4, ElevenLabs TTS) can be assembled in 20–30 minutes without a single line of code. So, all we need to do is write a bit of code for a Telegram bot that utilizes GPT's capabilities. First, we need to create the bot itself using @BotFather, and then install the libraries:
pip install python-telegram-bot openai elevenlabs
My minimal code:
import openai
from telegram import Update
from telegram.ext import Updater, MessageHandler, Filters, CallbackContext
from elevenlabs import generate, set_api_key
openai.api_key = "YOUR_OPENAI_KEY"
set_api_key("YOUR_ELEVENLABS_KEY")
TELEGRAM_TOKEN = "YOUR_TELEGRAM_TOKEN"
def handle_voice(update: Update, context: CallbackContext):
voice = update.message.voice.get_file()
voice.download("user_voice.ogg")
with open("user_voice.ogg", "rb") as audio:
transcript = openai.Audio.transcribe("whisper-1", audio)
user_text = transcript["text"]
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "You are a crypto market analyst. Respond briefly."},
{"role": "user", "content": user_text}
]
)
assistant_text = response["choices"][0]["message"]["content"]
audio_data = generate(text=assistant_text, voice="Antoni")
with open("assistant_voice.mp3", "wb") as f:
f.write(audio_data)
update.message.reply_voice(voice=open("assistant_voice.mp3", "rb"))
updater = Updater(TELEGRAM_TOKEN)
updater.dispatcher.add_handler(MessageHandler(Filters.voice, handle_voice))
updater.start_polling()
updater.idle()
Each request is processed in 10–15 seconds — instead of searching for hours, traders simply ask and get an answer.
Voice Automation of Business Processes — Cases and Examples
Voice automation is already transforming routine tasks — automating up to 70% of repetitive duties.
Case 1: Support Automation
An IT company received up to five hundred calls per day, 60% of which were repetitive questions. A voice bot based on GPT, Whisper, and ElevenLabs reduced the average handling time from 5 minutes to 1 minute, lowered operator load by 65%, and saved 120 hours per month.
Case Number Two: Voice Analyst for Traders (ASCN.AI)
Traders spend 30-60 minutes a day analyzing news and on-chain data. Our voice agent in Telegram collects and voices summaries for tokens in 30 seconds. This saves up to 40 hours a month on analytics. Averaged values reported by clients following implementation indicate that profitability increased by 15-20%.
More about the ASCN.AI case during the Falcon Finance crash
Case 3: Automation of Restaurant Order Taking
A restaurant chain had about 200 calls per day. The application of a voice bot implemented using Yandex SpeechKit and GPT-4 required no human intervention in 90% of calls, reduced order loss from 15% to 2%, and increased revenue by 8%.
Investments pay off in 2–6 months — particularly noticeable in customer support, trade, analytics, and HR.
Points to Consider and Implementation Notes
- Give the assistant clear instructions via a system prompt: who it is and what its output response style should be.
- Keep no more than 10–15 recent messages in memory — this reduces request costs while maintaining quality.
- Implement recognition error handling: ask to check or clarify misunderstood “what is this” words.
- Add fallback scenarios — if the assistant is unclear, have it ask again.
- Break long responses into short phrases convenient for auditory perception.
At ASCN.AI, a session can consist of up to 20 messages — maintaining a coherent context in the dialogue.
Security and Confidentiality of Voice Data
- Data must be sent exclusively via the secure HTTPS protocol.
- Audio files should be deleted immediately after processing or no later than 24 hours.
- Modeling logs should be anonymized, excluding personal information.
- API keys must be stored in locations inaccessible from the outside and never included in public code.
- Comply with GDPR and local personal data laws. Obtain user consent for processing personal data, provide options for deletion, and so on. For financial and medical projects, on-premise solutions are preferred.
Monitor and Optimize Performance
- Log the time at each stage: ASR, NLP, TTS.
- Ensure the API error rate does not exceed 1%.
- Analyze speech recognition accuracy based on feedback and logs.
- Optimize API costs: improve prompts, shorten responses.
- Cache popular answers — this can reduce GPT load by up to 50%.
- Use asynchronous processing — this will reduce response time during parallel requests.
- Store audio files on a CDN for fast delivery.
At ASCN.AI, the cost of a request is about $0.06; processing takes 10 seconds. Prompt optimization allowed us to save a quarter of the budget without sacrificing quality.
Frequently Asked Questions (FAQ)
How long does it take to create a voice assistant?
It takes only 2–4 hours to develop a basic prototype using the OpenAI API. A production version with integration, logging, and security takes 1–2 weeks. On no-code platforms (ASCN.AI, n8n), you can launch in 1–2 days without any programming.
Are programming skills required?
For no-code solutions — no. For complex scenarios and custom integrations, basic knowledge of Python is useful. However, no-code builders allow you to assemble a powerful assistant visually, without code.
What are the limitations of voice AI?
ASR loses accuracy in noise — down to 70–80%, whereas in quiet environments it reaches 95%. GPT sometimes generates inaccurate responses — so-called hallucinations. TTS does not always perfectly convey complex intonation. There are also request limits and potential delays during high API load.
How can I protect data from leaks?
Use HTTPS, delete audio after processing, anonymize logs, keep keys secure, comply with personal data laws, and use on-premise systems for highly sensitive information.
Disclaimer
The information in this article is for general informational purposes and does not replace investment, legal, or security advice. The use of AI assistants requires a conscious approach and an understanding of the functions of specific platforms.